Coursera Kaggle 강의(How to win a data science competition) week 2-1 EDA 요약
in Data on Machine Learning
Exploratory Data Analysis
1.Exploratory Data Analysis
EDA란 무엇이며 왜 해야하나 ?
- EDA란 데이터를 조사하고 이해하고 익숙해지는 과정이다.
익명처리,암호화,전처리과정,난독화등을 거친 데이터를 분석하기 위해서는 EDA가 필수적이다. 데이터를 시각화하면 패턴을 볼 수 있다.
EDA를 왜 하는가 ?
- 데이터를 더 잘 이해하게 된다.
- 데이터에 대한 직감이 생긴다.
- 가설을 만들 수 있다.
- 통찰력을 얻는다.
바로 모델생성, Stacking, Mixing 과 같은 것으로 코드를 작성하기 보다는 EDA를 통해서 데이터를 이해하는 노력을 해야 장기적으로 실력을 향상 시킬 수 있다.
EDA의 가장 대표적인 방법은 시각화(Visualization)이다.
시각화를 통해서 아이디어를 얻고, 아이디어로부터 가설을 세워서, 그것이 맞는지 시각화하여 확인하라.
EDA를 함으로써
- 데이터를 더 친숙하게 느끼게 되며,
- magic feature를 찾게 될 수 있다.
2. Building Institution about the data
2.1. 도메인 지식 얻기
일반적으로 Wikipedia나 구글 검색으로 통해서 얻는다. 데이터에 대한 이해가 있으면 EDA를 통해서 얻는게 훨씬 더 많아진다.
2.2. 데이터가 직관적인지 확인
Age항목에서 336을 발견한다면 당연히 잘못된 데이터라고 판단이 된다.
Google AdWords 데이터의 경우 광고 노출보다 클릭수가 더 클 수는 없다. 잘못된 데이터가 있는 경우 is_correct라는 feature를 추가하여 오류가 있는 행을 표시하는 것도 도움이 될 수 있다.
2.3. 데이터 생성방법 이해
train / test 데이터가 다른 방법으로 생성되었는지 확인해야 한다. 예를 들어 train 데이터는 모두 workday에 관한 데이터이고, test 데이터는 모두 holiday라던지, 특정 feature에 의한 분포도가 완전히 다른 경우라고 할 때는 비슷한 기준으로 표현되도록 데이터를 가공하던지, 아니면 해당 feature를 제거하는게 더 좋을 수 있다.
3. Exploring anonymized data (익명화 데이터)
일부 대회에서는 경쟁사로의 데이터 유출을 회피하고자 데이터를 비식별화하기도 한다. 그 방법으로는 문자열 값을 해쉬화 하거나 컬럼명을 무의미하게 x1, x2, … 로 만든다.
- 데이터 디코딩을 시도
- 숫자형, 범주형 등 데이터 유형을 확인
- feature 간의 관계 및 그룹화 가능여부를 확인
df.dtypes
df.info()
x.value_counts()
x.isnull()
4. Visualizations (시각화)
4.1. 단일 feature 분석
- Histogram
데이터를 bin으로 나눠서 각 bin별 몇 개의 포인트가 있는지를 표시
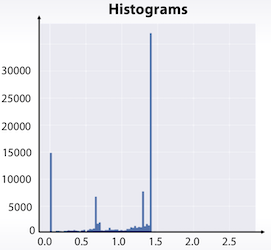
plt.hist(x)
히스토그램이 이상할 경우 log를 취한다던지의 가공을 하면 좀 더 명확해 지는 경우도 있다.
- Plot (index vs value)
각 index 별로 어떠한 값을 가지는지 점으로 표시.
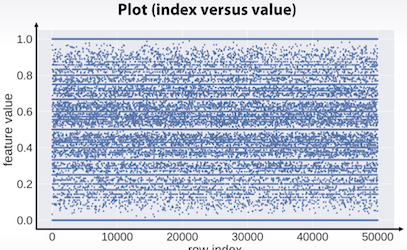
plt.plot(x,’.’)
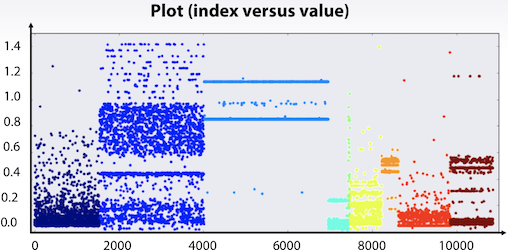
plt.scatter(range(len(x)), x, c=y)
- Feature Statistics
통계적 수치 확인
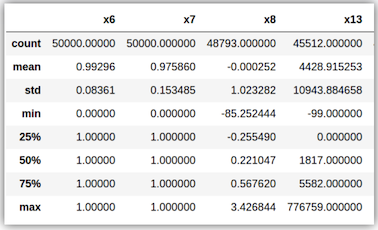
df.describe()
x.mean()
x.var()
x.value_counts()
x.isnull()
4.2. 2개 feature의 관계 분석
- Scatter Plot
plt.scatter(x1, x2)
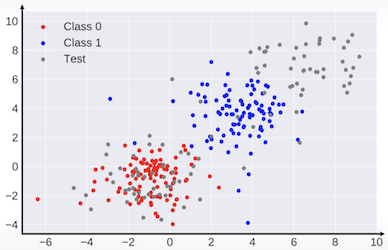
위 그림은 train 데이터의 target 값에 따라 빨간/파란색으로 표현했으며, test 데이터는 회색으로 표시했다. 데이터의 분포가 train/test가 서로 다르다는 것이 확인 가능하다.
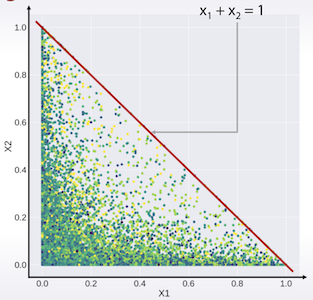
X2 <= 1 - X1 관계가 확인 가능하다.
Pandas는 모든 feature쌍의 scatter plot을 그려주는 기능을 제공한다.
pd.scatter_matrix(df)

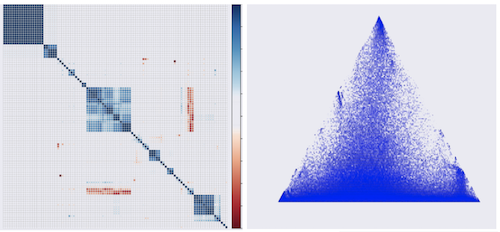
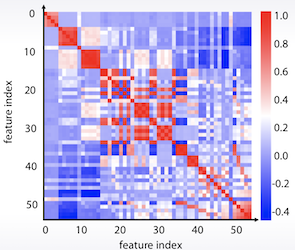
- Correlation Plot
df.corr(), plt.matshow( ... )
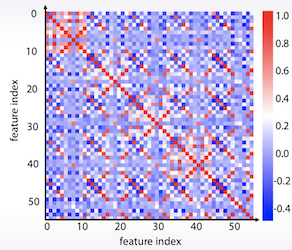
데이터를 K-means를 통해 군집화 한다던지, 새로 순서를 정렬하는 것이 데이터 패턴을 파악하는데 도움이 되기도 한다.
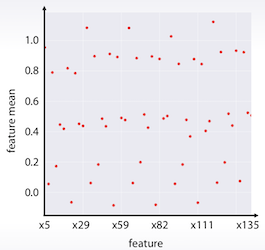
4.3. feature 그룹의 분석
df.mean().sort_values().plot(style=’.’)
각 feature 별로 평균값을 계산하여 그려 볼 수도 있다.
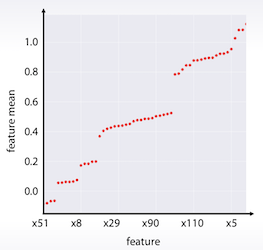
이 것을 통계기반으로 정렬해서 보면 다음과 같다.
5. Dataset Cleaning (데이터 정제)
5.1. Constant feature 확인
traintest.nunique(axis=1) == 1
모든 값이 같은 feature를 확인하여 제거
5.2. 중복된 feature 확인
traintest.T.drop_duplicates()
중복된 값을 가질 경우 1개만 남겨두고 제거하는 것이 좋다.
범주형 데이터에서 값은 다르지만 똑같은 기능을 하는 경우도 있을 수 있다.
for f in categorical_feats:
traintest[f] =raintest[f].factorize()
traintest.T.drop_duplicates()
모든 범주형 feature를 다시 encoding하여 비교하면 쉽게 찾을 수 있다.
5.3. 중복된 row 제거
먼저 중복된 row의 label이 같은지를 확인해야 한다. 같다고 판단이 되면 제거를 하는 것이 성능에 좋다.
train과 test에도 중복된 row가 있을 수 있다.
5.4. 데이터가 shuffle되었는지 확인
shuffle 되지 않은 데이터에서는 누락된 데이터를 유추 할 수 있는 방법들이 있을 수 있다.
이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
