Coursera Kaggle 강의(How to win a data science competition) week 4-4 Ensemble 요약
in Data on Machine Learning
Ensemble
- 여러가지 머신 러닝 모델을 결합하는 방법
1. Averaging (or blending)
여러 모델의 결과값의 평균을 취함
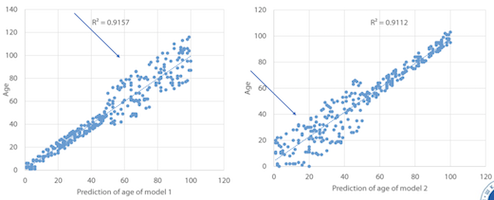
위와 같은 2개의 모델이 있을 경우
1.1 Averaging
단순 평균
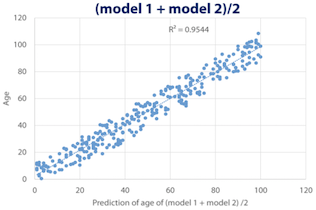
1.2 Weighted averaging
가중 평균
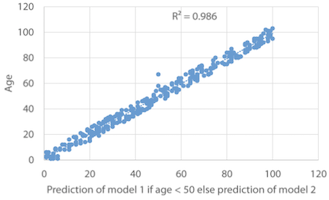
1.3 Conditional averaging
조건 평균
2. Bagging
동일한 모델의 약간 다른 버전의 평균. 대표적인 예로 Random Forest
Bagging을 하는 이유로는 모델이 가지는 2가지 문제를 해결하기 위해서다.
- Underfitting : Bias
- Overfitting : Variance
Bagging용 파라메터
- Random seed
- Row (Sub) sampling or Bootstrapping
- Shuffling
- Column (sub) sampling
- Model-specific parameters
- Number of models (or bags) : 보통 10 이상으로 하지만, 어느 순간 성능의 정체상태가 온다.
Bagging 예제 코드 : BaggingClasifier and BeggingRegressor from sklearn
model = RandomForestRegressor()
bags = 10
seed = 1
bagged_prediction = np.zeros(test.shape[0])
for n in range(0, bags):
model.set_params(random_state = seed + n)
model.fit(train, y)
preds = mpdel.predict(test)
bagged_prediction += preds
bagged_prediction /= bags
3. Boosting
Boosting이란 이전 모델의 성능을 고려한 방식으로 순차적으로 구축되는 모델의 가중 평균으로 구하는 방식이다.
Boosting에는 2가지 방법이 있다.
- Weight based Boosting (웨이트 기반)
- Residual based Boosting (잔여 오류 기반)
3.1 Weight based Boosting
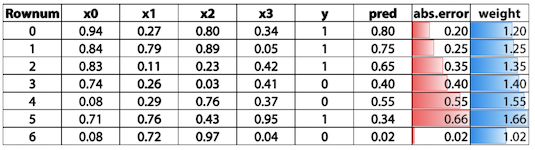
위 예에서 우리가 구한 predict값이 pred라고 했을시 타겟(y)과의 절대차를 abs.error라고 했을 경우, 1에다가 절대차를 더한 값으로 weight로 설정한다. weight를 계산하는 방법은 이것 말고도 다른 방법들이 있다.
다음에 학습시킬 때는 이 weight를 feature에 추가하여 진행한다.
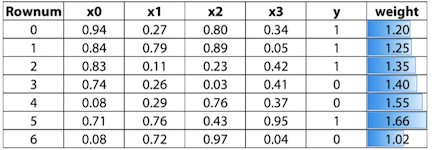
Weight based Boosting의 parameter들
- Learning rate
- Number of estimators
- Input model
- Sub boosting type : AdaBoost (sklearn), LogitBoost (Weka - Java)
3.2 Residual based boosting
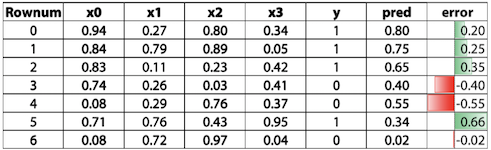
이번에는 pred값으로 error값을 구한 다음 그 error를 타겟으로 해서 학습을 진행한다.
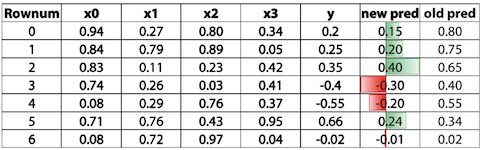
그렇게 학습한 뒤에 새로운 new_pred값에 기존 pred 값을 더하여 최종 predict값으로 설정한다.
위 그림에서 Rownum = 1의 경우 0.2 + 0.75 = 0.95가 최종 predict가 되는 것이며, Rownum = 4의 경우에는 -0.2 + 0.55 = 0.35가 되는 것이다. 이런식으로 계산하면 정확도가 많이 향상된다.
Weight based Boosting의 parameter들
- Learning rate
- Number of estimators
- Row (sub) sampling
- Column (sub) sampling
- Input model : tree 모델이 좋음
- Sub boosting type: Fully gradient based, Dart
Residual based로 구현된 모델로는 XGBoost, LightGBM, H2O’s GBM, CatBoost, Sklearn’s GBM 등이 있다.
4. Stacking
여러가지 모델로 학습한 결과로 새로운 데이터셋을 만드는 방법이다. 앙상블 방법 중 가장 인기가 많다.
1992년 Wolpert에 의해서 stacking이 소개 되었다. 그것은 다음과 같다.
- train 데이터를 2개로 나눈다.
- 그중 하나로 여러 가지 모델을 학습시킨다. (base learner)
- 2번에서 생성한 모델들로 prediction을 진행한다
- 3번에서 생성한 prediction으로 다른 모델을 학습한다. (higher level learner)
Stacking example
from sklearn.ensemble import RandomForestRegressor
from sklearn.lear_model import LinearRegression
import numpy as np
from sklearn.model_selection import train_test_split
training, valid, ytraining, yvalid = train_test_split(train, y, test_size=0.5)
model1 = RandomForestRegerssor()
model2 = LinearRegression()
model1.fit(training, ytraining)
model2.fit(training, ytraining)
preds1 = model1.predict(valid)
preds2 = model2.predcit(valid)
test_preds1 = model1.predict(test)
test_preds2 = model2.predcit(test)
stacked_predictions = np.column_stack((preds1, preds2))
stacked_test_predictions = np.column_stack((test_preds1, test_preds2))
meta_model = LinearRegression()
meta_model.fit(stacked_predictions, yvalid)
final_predictions = meta_model.predict(stacked_test_predictions)
4. StackNet
Stacking을 Neural Network 방식으로 여러 Layer로 구성한 방법이다.
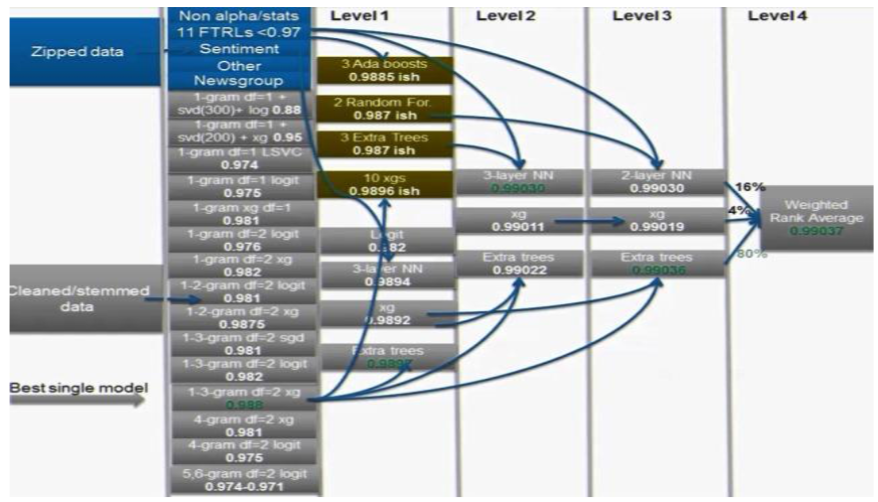
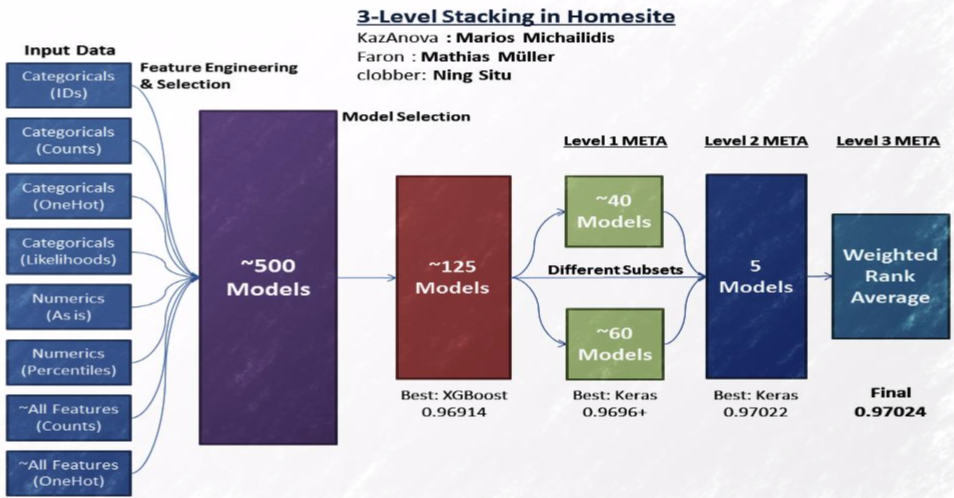
앞서 본 Stacking에서는 train을 2부분으로 나누어서 진행하였다. StackNet에서 Layer를 추가해야한다고 한다면 이걸 다시 나누어야 한다.
우리가 충분히 많은 데이터셋을 가지고 있지 않다면 끊임없이 나누지 않고 작업을 수행해도 된다.
데이터를 나눌때 K-Fold 패러다임을 사용하는 방법이 있다. K = 4 라는 상황을 가정한다면 train 데이터를 4개로 나누어 4개의 모델에 대해서 그 중 3개로 학습하고 1개로 validation한 모델들을 만든 다음 전체 train 데이터에 predict한 결과를 생성하여 Stacking을 수행한다. 또는 평균을 취할 수도 있다.
StakNet에서는 하지만 Neural Network의 back propagation이 지원되지는 않는다. 왜냐면 모든 모델이 다 미분이 가능하지는 않을 수 있기 때문이다.
1st level tips
- Diversity based on algorithms:
- 2-3 Gradient boosted trees (LightGBM, XGBoost, H2O, CatBoost)
- 2-3 Neural Nets (Keras, PyTouch)
- 1-2 ExtraTrees / Random Forest (sklearn)
- 1-2 Linear Models as in logistic/ridge regression, linear svm (sklearn)
- 1-2 knn models (sklearn)
- 1 Factorixation machine (libfm)
- 1 Svm with nonlinear kernel if size/memory allows (sklearn)
- Diversity based on input data:
- Categorical features: One hot, Label encoding, Target encodingm Frequency
- Numerical features: Outliers, Binning, Derivatives, Percentiles, Scaling
- Interactions: col1*/+-col2, groupby, unsupervised
Subsequenct level tips
- Simpler (or shallower) Algorithms:
- Gradient boosted trees with small depth (like 2 or 3)
- Linear models with high regularization
- Extra Trees
- Shallow networks (as in 1 hidden layer)
- Knn with BrayCutis distance
- Brute forcing a search for best linear weights based on cv
- Feature engineering
- pairwise differences between meta features
- row-wise statistics like averages or stds
- Standard feature selection techniques
- For Every 7.5 models in previous level we add 1 in meta (empirical)
- Be mindful of target leakage
이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
