Coursera Kaggle 강의(How to win a data science competition) week 3,4 Advanced Feature Engineering 요약
in Data on Machine Learning
1. Mean encodings
- Categorical feature로 groupby하여
target의 mean값을 feature로 추가- mean뿐 아니라 median, std, min, max 등 해당 데이터의 성격을 잘 나타내는 통계 연산
ex) 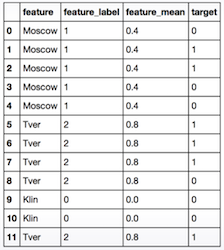
위 그림의 경우
- Moscow : 1 2개, 0 3개 -> 0.4
- Tver : 1 4개, 0 1개 -> 0.8
- Klin : 0 all -> 0.0
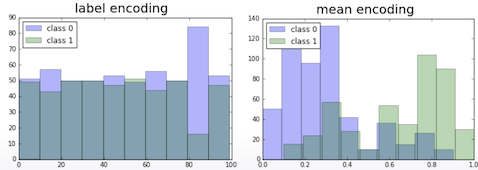
Label encoding의 경우 단순히 순서에 의해 부여된 숫자일뿐 target과의 관련성이 전혀 없지만, Mean encoding의 경우 0 ~ 1 사이 값으로 target값과 연관성이 있이 있다. 특히 0인 것과 아닌 것은 완전히 구분이 된다.
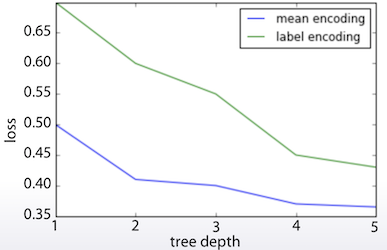
더 짧은 tree로도 더 좋은 성능을 발휘한다.
적용 방법들
- Likelihood : Goods / (Goods + Bads) = mean(target)
- Weight of Evidence = ln(Goods / Bads) * 100
- Count = Goods = sum(target)
- Diff = Goods - Bads
cf. Goods : 1의 개수, Bads : 0의 개수
tree 개수가 증가하면면서 정확도가 계속 증가한다면 아직 overfitting이 아니라는 뜻이다. 이럴 때 mean encoding을 적용하여 더 빨리 정확도를 올릴 수 있다. 하지만 overfitting은 항상 주의해야 한다. 왜냐면 train, validation의 비율이 다를 경우 overfitting된 상태라면 결과가 좋지 않다.
2. Regularization (정규화)
2.1 CV Loop regularization
- 매주 직관적이고 강력한(robust)한 방법
y_tr = df_tr['target'].values
skf = StratifiedKFold(y_tr, 5, shuffle=True, random_state=123)
for tr_ind, val_ind in skf:
X_tr, X_val = df_tr.iloc[tr_ind], df_tr.iloc[val_ind]
for col in cols:
means = X_val[col].map(X_tr.groupby(col).target.mean())
X_val[col+'_mean_target'] = means
train_new.iloc[val_ind] = X_val
prior = df_tr['target'].mean() # global mean
train_new.fillna(prior, inplace=True)
- Fold를 나누어서 validation set의 feature를 train set의
mean encoding으로 설정 (보통 4~5 정도면 충분)- NA값은 global mean으로 설정
단 LOO (Leave one out)같은 극단적인 경우는 주의
2.2 Smoothing
다른 regularization을 얼만큼 적용시킬지를 Alpha값을 이용하여 설정 \[\frac{mean(target)*nrows + globalmean*alpha}{nrows + alpha}\]
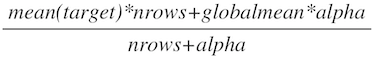
2.3 Noise
통상적으로 노이즈를 추가하면 encoding의 품질이 저하되어서 얼마나 넣어야 할지 고민을 많이 해야 한다. LOO와 함께 사용하면 효과적이다. (자세한 설명이 없음)
2.4 Expanding mean
cumsum = df_tr.groupby(col)['target'].cumsum() - df_tr['target']
cumcnt = df_tr.groupby(col).cumcount()
train_new[col+'_mean_target'] = cumsum/cumcnt
- CatBoost애는 내장된 방식
- Leakage를 줄일 수 있으나 품질이 불규칙적이다.
3. Generalizations and extensions
3.1 Regression과 Multiclass
- Regression : percentile, std, distribution bin등의 통계함수를 추가
- Multiclass : 각각의 class별로 encoding
3.2 Many-to-many relation
- Cross product
- Statistics from vectors
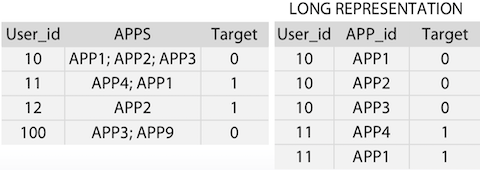
APPS를 각각의 row로 나눔
3.3 Time series
time-series 데이터의 경우 앞의 방법들을 사용하는게 의미 없을 수 있다.
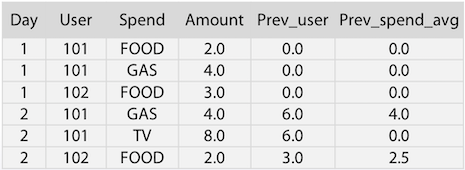
위 예제의 경우 Day-User-전날 Amount 합과 Day-Spend-전날 Amount 평균을 feature로 추가하였다.
3.4 Interactions and numerical features
- numeric feature를 bin하여 categorical feature로 만드는 방법이다.
- EDA 과정을 통해서 숫자상의 어떤 점에서 target값의 분기가 일어나는지를 관찰하는 것이 유용하다.
- feature 2개 이상이 상호작용적으로 동작하는 경우에는 그것들을 합하여
mean encoding하는 방법도 있다.
Correct validation reminder
- Local experiments: ‒ Estimate encodings on X_tr ‒ Map them to X_tr and X_val ‒ Regularize on X_tr ‒ Validate model on X_tr/ X_val split
- Submission: ‒ Estimate encodings on whole Train data ‒ Map them to Train and Test ‒ Regularize on Train ‒ Fit on Train
- Main advantages: ‒ Compact transformation of categorical variables ‒ Powerful basis for feature engineering
- Disadvantages: ‒ Need careful validation, there a lot of ways to overfit ‒ Significant improvements only on specific datasets
4. Statistics and distance based features
1개의 feature를 groupby하여 계산한 다양한 통계값을 활용
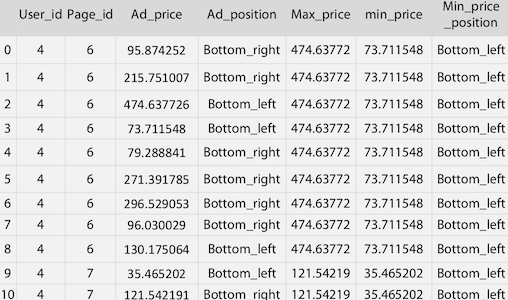
위 그림의 경우 [User_id, Page_id, Ad_price, Ad_position]은 원래 있던 feature들이고 [Max_price, min_price, Min_price_position]은 추가로 생성한 feature들이다.
- Max_price : Page_id로 groupby한 MAX(Ad_price)
- min_price : Page_id로 groupby한 MIN(Ad_price)
- Min_price_position : Page_id내에서 Ad_price == min_price 에 해당하는 Ad_posision
gb = df.groupby(['user_id', 'page_id'], as_index=False)
.agg({'ad_price': {'max_price': np.max, 'min_price': np.min}})
gb.columns = ['user_id', 'page_id', 'min_price', 'max_price']
df = pd.merge(df, gb, how='left', on=['user_id', 'page_id'])
위에 예제로 보인 featue뿐만 아니라 다양한 것들을 생각해 볼 수 있다.
- user가 얼마나 많은 page를 방문했는지
- price의 표준편차
- 가장 많이 방문한 page
- 등등…
그런데, groupby 할 수 없는 feature는 어떻게 해야할까 ? 그럴 경우 kNN과 같은 클러스터링 기법들로 대체가 가능하다.
- 500m, 1000m 이내에 있는 집의 수
- 500m, 1000m 이내에 있는 집의 평균 평당가
- 500m, 1000m 이내에 있는 학교/슈퍼마켓/주차장 수
- 가장 가까운 지하철역
사례: Springleaf에 사용된 kNN feature들
- 모든 변수에 대해서
mean encoding - 모든 point에서 Bray-Cutis metric을 이용하여 2000-NN을 찾음
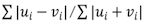
- 2000개의 이웃으로 다양한 feature들을 계산
- 5, 10, 15, 500, 2000개의 NN의 target mean값
- 10개의 가까운 이웃들과의 distance mean값
- 10개의 가까운 이웃중 target이 1/0인 것과의 distance mean
- 등등…
5. Matrix Factorizations for Feature Extraction
feature 추출에 행렬 분해 기법을 활용하는 방법들이다.
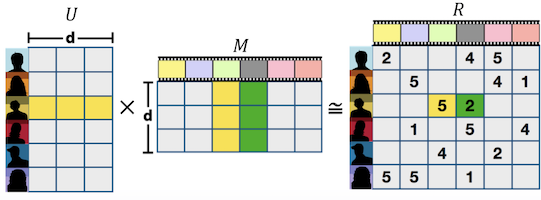
예를 들어 사용자별로 연령, 지역, 관심사, 성별 등의 feature들이 있고, 이러한 정보에 따른 등급 정보가 있는 경우 이 둘을 matrix 곱으로 표현할 수 있다.
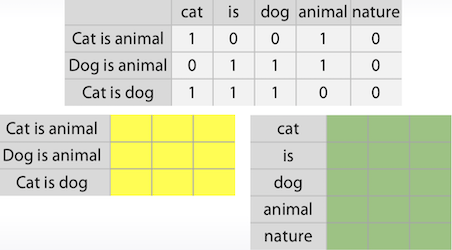
text 분류기의 경우에도 보통 sparse matrix로 표현되는 것을 각각의 matrix로 표현하는 것이 가능하다.
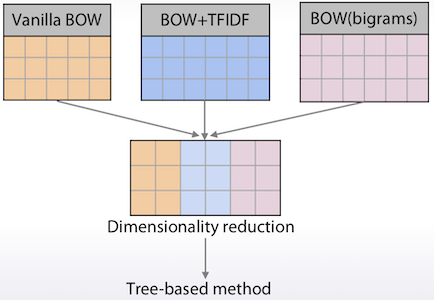
여러 방법들을 섞어서 사용하기도 한다.
Matrix Factorization 진행시
- 몇개의 column만을 적용시키기도 함.
- 다양한 것의 추가가 가능하다. (Ensemble에 효과적)
- 손실 변환(lossy transformation)이다.
- 특정 작업에 의존적이므로 경험적으로 해야한다.
- factor는 보통 5 ~ 100 사이로 설정한다.
sklearn에 Matrix Factorization의 구현체가 있음
SVD,PCA: MF용 stadard toolTruncatedSVD: sparse matrices용NMF(Non-negative MF) : count-like한 데이터에 좋음. 모든 데이터가 non-negative인게 보장됨
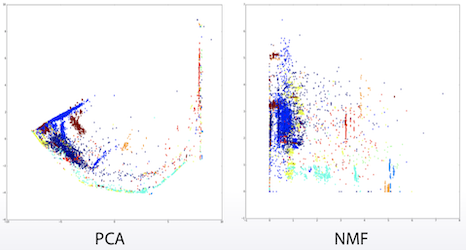
위 그림을 보면 NMF를 적용하니 linear model처럼 분리되는 것을 볼 수 있다.
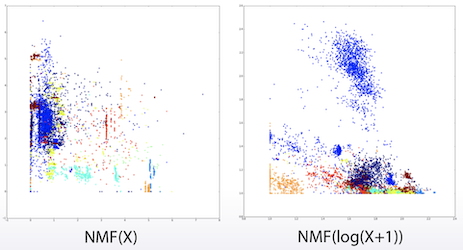
log(X+1)를 적용하는 등의 다양한 trick을 시도해 볼 수 있다.
MF 적용시 train, test를 각각따로 적용하면 안된다. 둘을 함께 적용시켜야 올바른 결과가 나온다.
- Wrong way
pca = PCA(n_components=5) X_train_pca = pca.fit_transform(X_train) X_test_pca = pca.fit_transform(X_test) - Right way
X_all = np.concatenate([X_train, X_test]) pca.fit(X_all) X_train_pca = pca.transform(X_train) X_test_pca = pca.transform(X_test) - MF는 차원 축소와 feature 추출에 좋다.
- categorical feature를 좀 더 현실적인 값으로 변경해준다.
- linear model화 되도록 적절한 trick을 적용하면 유용하다.
6. Feature interactions
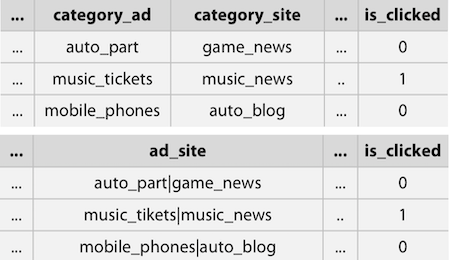
위 경우를 보면 category_ad와 category_site가 있는데, 정작 중요한 것은 그 둘의 조합이다. 이 경우 그 둘을 concat하여 ad_site로 하는게 더 효율적일 수 있다.
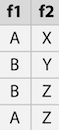
위 경우에서 FI 방법에 대해서 2가지로 생각해보다.
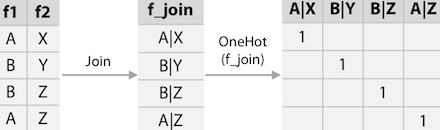
첫번째 방법은 앞에서 본 경우와 같이 f1과 f2를 조합하여 one-hot을 적용시킨 방법이다.
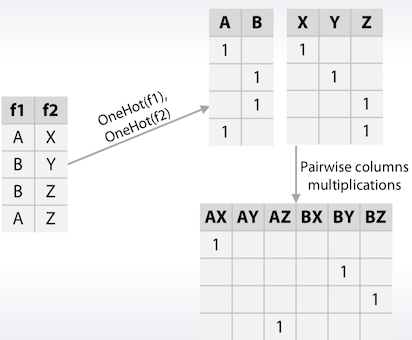
두번째 방법으로는 f1과 f2를 각각 one-hot한 다음 그 둘을 조합한다.
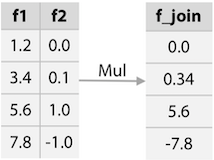
FI의 또 다른 예로 f1과 f2가 둘 다 numeric일 경우 그 둘을 곱하는 방법도 있다.
이렇게 곱, 합, 차, 나누기 등을 적용하는 방법들을 생각해 보자.
모든 feature에 그렇게하기에는 조합을 할 수 있는 경우의 수가 너무나도 많다.
어떻게 유의미한 것들만을 골라내서 차원을 줄일 수 있을까 ?
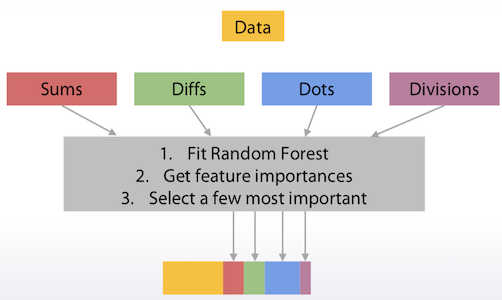
- Random Forest로 일단 돌려본 다음
- Feature Importance를 보고
- 유의미한 것들만을 추출
Decision Tree를 이용하여 feature를 추출하는 방법도 있다.
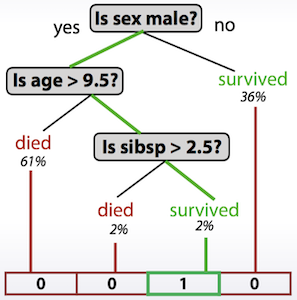
# In sklearn
tree_model.apply()
# In XGBoost
booster.predict(pred_leaf=True)
7. tSNE
앞서 NMF를 이용하여 linear model에 가깝게 변화시키는 것을 본 적이 있다.
7.1 Manifold Learning
비선형 차원 축소 방법 (non-linear method of dimensionality reduction)
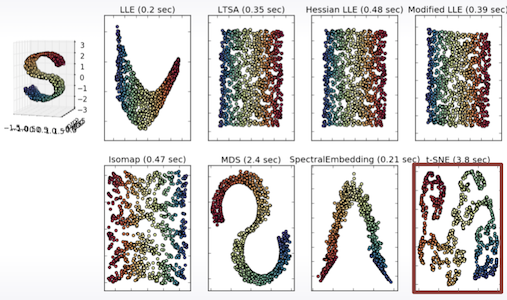
데이터를 차원변환시켜서 해석하기 쉬운형태로 분리하는게 가능하다.
7.2 MNIST의 tSNE 반영 결과

2차원 공간에 투영된 700차원 공간
Perplexity hyperparameter를 어떻게 설정하느냐에 따라 결과가 달라진다.
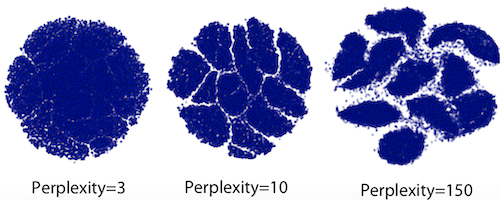
여기에 대해 정리된 내용은 다음과 같다.
Perplexityhyperparameter값에 크게 의존적이다.- 5 ~ 100 사이 값이 결과가 대체로 좋았다.
- 확률적 특징때문에 같은 데이터, perplexity 갑이라도 다른 결과가 나온다.
- train, test는 같이 투영되어야 한다.
- feature가 많으면 오래 걸린다.
- 그래서 보통 투영하기전에 차원축소를 한다.
- tSNE의 구현체는
sklearn에 있다.- 하지만, 파이썬의 개별패키지로 하는게 더 빠르기 때문에 추천하지는 않는다.
이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
