Coursera Kaggle 강의(How to win a data science competition) week 2-2 Validation 요약
in Data on Machine Learning
Validation
Validation이란 target이 있는 train 데이터셋 중 일부를 validation 데이터로 나누어서 train 데이터 만으로 모델을 학습시킨 뒤 validation 데이터로 모델의 품질을 검증하는 과정을 뜻한다. 이렇게 하는 가장 큰 이유는 이후 target이 없는 test 데이터를 가지고 predict 할 때 좋은 성능이 나오는지에 대해서 검증이 가능하기 때문이다. 왜 이게 도움이 되는지를 알기 위해서는 Overfitting에 대한 이해가 필요하다.
1.Overfitting
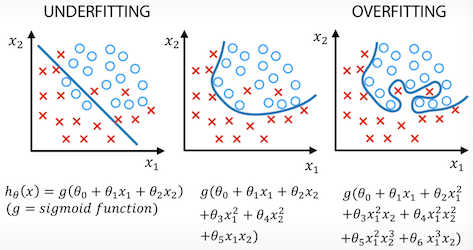
- Underfitting : 모델이 학습이 덜 되어서 너무 단순한 모양이 띄게 된다면 정확한 예측이 힘들어진다. 위 그림에서 왼쪽 그림의 경우 모델이 단순하여 아래에 있는 3개의 파란원과 위쪽에 있는 빨간X를 제대로 예측못하게 된다.
- Overfitting : 모델이 너무 train 데이터에 정확하게 맞도록 학습이 되어 버리면, 일반적인 상황에서 제대로 예측을 못할 수도 있다. 위 그림에서 오른쪽 그림이 그러한 경우인데, 노이즈가 섞여있는 train 데이터의 모두에 대해서 예측을 하려고 학습을 한 결과 굉장히 복잡한 모델이 되었다. 이 경우 일반적인 데이터들에 대해서는 예측이 빗나갈 수도 있다.
중간의 그림같이 train 데이터 중 일부에 대해서는 맞추지 못하더라도 일반적인 형태의 예측력을 가장 좋게 모델을 학습시켜야 한다.
그럼 어느 정도 학습해야 가장 좋은 모델인지 어떻게 할 수 있을까 ?
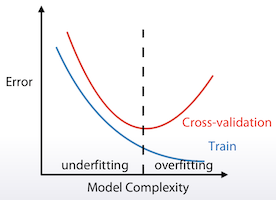
그걸 알기 위해서는 앞에서 언급한 validation 데이터가 필요하다. 학습을 하면 할수록 train 데이터에 대해서는 점점 더 error가 줄어들 수 밖에 없다. 하지만 validation 데이터에 대해서는 특정 시점 이후에 점점 더 error가 늘어날 수도 있다. error가 늘어나기 직전의 지점이 가장 학습이 잘 된 모델의 상태라고 할 수 있다.
2. Validation Strategies
Validation 데이터를 나누는데는 총 3가지 전력이 있다.
- Hold-out
- K-Fold
- Leave-one-out
2.1. Hold-out (ngroups=1)
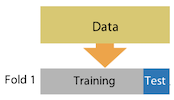
sklearn.model_selection.ShuffleSplit
단순하게 데이터를 train, validation으로 나누는 방법이다. 통상적으로 7:3으로 많이 나눈다.
2.2. K-Fold (ngroups=k)
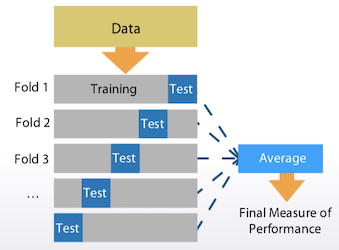
sklearn.model_selection.Kfold
train 데이터를 k개로 나누어서 그중 1개를 validation 데이터로 나머지를 test 데이터로 하여 k번 반복을 한다. 이 방법의 핵심은 반복하면서 train, validation에 전체 데이터를 모두 사용했다는 점이다. 이렇게 나온 각각의 모델의 성능에 평균값으로 전체 모델의 성능을 결정한다.
2.3. Leave-one-out (ngroups=len(train))
sklearn.model_selection.LeaveOneOut
K-Fold의 특수한 케이스이다. K값을 train 데이터 개수만큼 한 것이다. 이러면 1개의 데이터만을 validation으로 하고 나머지를 train 데이터로 설정하여 학습한다. train 데이터의 개수가 너무 적을 경우에 주로 사용하는 방법이다.
2.4. Stratification
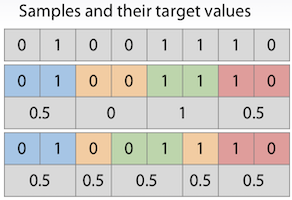
train 데이터가 너무 적을 경우 train / validation으로 데이터를 나눌 때 한쪽의 데이터만 편향되게 나뉘어 질 수 있다. 예를 들어서 train 데이터는 모두 target값이 1이고, validation은 모두 0 일 수도 있다. 그래서 각각의 fold에 들어가는 데이터의 비율을 균일하게 맞추는 과정이 필요 할 수도 있다.
3. Data Splitting Strategies
실제 해결해야 할 문제와 가장 유사한 형태로 train / validation을 나누는 것이 좋다.
3.1. Random, Rowwise
각각의 row가 독립적인 경우에 유용하다. 가장 많이 사용하는 방법이다.
3.2. Timewise
시계열 데이터를 가지고 미래의 수요를 예측하는 문제의 경우
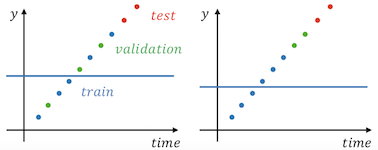
train 데이터를 시간 순서대로 배열하여 이전 값을 train으로 이후의 값들을 validation으로 나누는 방법을 생각해 볼 수 있다.
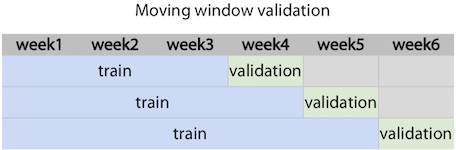
위 그림과 같이 Moving Window Validation을 사용할 수도 있다.
3.3. By ID
음악 추천 알고리즘을 개발해야 한다고 가정했을 경우, train과 validation에 같은 user가 둘 다 있어야만 의미가 있을 것이다.
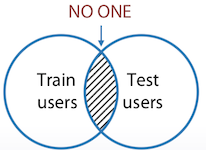
하지만 실제로 train과 test의 user가 전혀 겹치지 않을 수도 있다. 또는 id를 숨길 수도 있다. 이 경우에는 다른 feature들로 동일인 또는 동일그룹으로 id를 생성하는게 좋다.
3.4 혼합하여 적용
- 상점별로 미래 매상을 예측 -> 상점별 time-series로 나눔
- 여러 사용자로 검색쿼리를 받고 여러 엔진을 사용하는 경우 -> 사용자 id, 검색엔진 id를 조합하여 나눔
4. Common Validation Problems
각 Fold마다 점수 차이가 크다면 그 이유를 파악해야 한다.
데이터 자체가 그럴 수 밖에 없는 경우도 있다. 예를 들어서 매출 예측의 경우 1월 데이터로 train하여 2월 데이터로 validation한다면, 전체 날짜, 휴일의 날짜 등이 달라서 차이가 날 수 있다.
그게 아닌 경우에는 다음 사항들을 확인해 볼 필요가 있다.
- 데이터의 개수가 너무 적을 경우
- 데이터의 값이 너무 다양하고 일관성이 없는 경우
Instagram 사진으로 사람의 키를 예측하는 대회에서 train 데이터는 모두 여자만 있고, test 데이터는 모두 남자만 있다면 어떻게 해야할까 ?
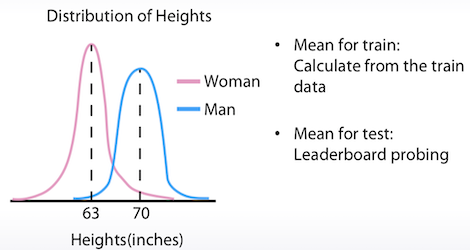
target 값을 분포로 구해서 평균 신장에 적용하는 방법을 생각해 볼 수 있다. 가장 간단하게는 predict 결과에다가 7 inch를 더하는 방법도 있다.
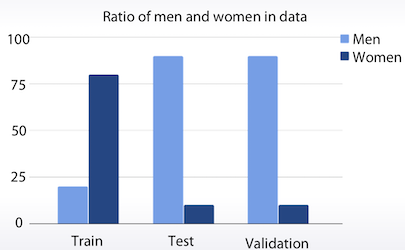
train과 test의 성비가 다른 경우라면 어떻게 해야 할까 ? validation을 test와 같은 비율로 만들어서 학습을 시키는 방법이 유용하다.
이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
