Coursera Kaggle 강의(How to win a data science competition) week 1 요약
in Data on Machine Learning
참고로 Kaggle 대회에 대한 소개, HW/SW 이야기 등은 모두 생략하였으며, Machine Learning 모델 개발에 관련된 내용들만을 정리했음
02.Competition mechanics
03.Recap of main ML algorithms
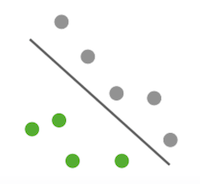
1. Linear Model
- 공간을 나누어서 구분
- ex) Logistic regression, SVM
- 하지만 원형으로 모여있는 경우에는 선형모델의 적용이 힘듬

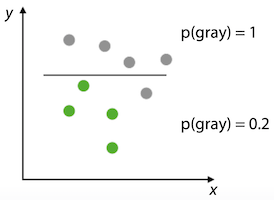
2. Tree-based Model
- Decision tree를 좀 더 복잡하게 구성하는 것이 기본 아이디어
- Divide-and-conquer 접근 방법
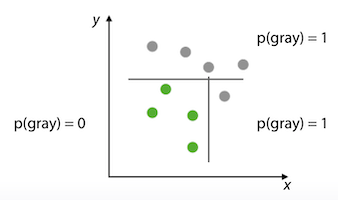
- 먼저 선하나로 devide한 다음 위쪽은 더 이상 나눌필요가 없으니 아래쪽만 다시 devide
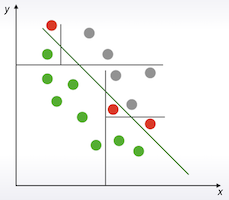
- 하지만 선형으로 쉽게 해결 되는 문제에 적용할 경우 훨씬 복잡해지며, 정확성도 더 떨어질 수 있음
- Random forest는 sklearn의 것이 가장 효과적이고, Gradient boosting은 XGBoost, LGBM이 좋음
- 대회에서 상위 랭킹자들이 많이 사용하는 알고리즘
3. k-NN (k-Nearest Neighbors)
- 가장 가까운 것을 따라가는 방식
- missing value를 채울때 유용
- sklearn의 kNN이 좋음. (custom distance funtion 지원)
4. Neural Nets
- 이미지, 사운드, 텍스트 시퀀스에 적합
- TensorFlow, Keras, MXNet, PyTorch
05.Feature preprocessing and generation with respect to models
02.Numeric features
- Numeric Feature의 전처리는 tree model과 아닌 것에 따라 다르게 접근해야 한다.
- Scaling : tree-model은 별로 상관이없고, non-tree의 경우 많은 영향을 미친다.
- MinMaxScaler : to [0, 1]
- 범위가 미리 정의되어 있는 경우 유용함.
- outlier가 없는 경우 사용
sklearn.preprocessing.MinMaxScalerX = (X X.min())/(X.max() X.min())
- StandardScaler : mean 0, std 1
sklearn.preprocessing.StandardScalerX = (X X.mean())/X.std()
- Rank : sort해서 indexing
scipy.stats.rankdata- ex) [1000, 1, 10] -> [2, 0, 1]
- Log Transform
np.log(1+x),np.sqrt(1+x)
- MinMaxScaler : to [0, 1]
- Scaling : tree-model은 별로 상관이없고, non-tree의 경우 많은 영향을 미친다.
- Feature 생성
- 데이터에 대한 지식이 필요.
- Explore Data Analysis
- ex)
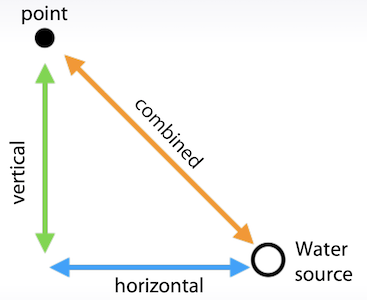
- 소수점 이하 부분만으로 feature 생성
- Combined = (horizontal ** 2 + vectical ** 2) ** 0.5
- 가격 / 면적 = 평당가
- Outlier 처리
- np.percentile 을 이용하여 1%, 99% 밖의 값을 제거하는 것이 효과적
- outlier 1개때문에도 model의 이상하게 될 수 있음
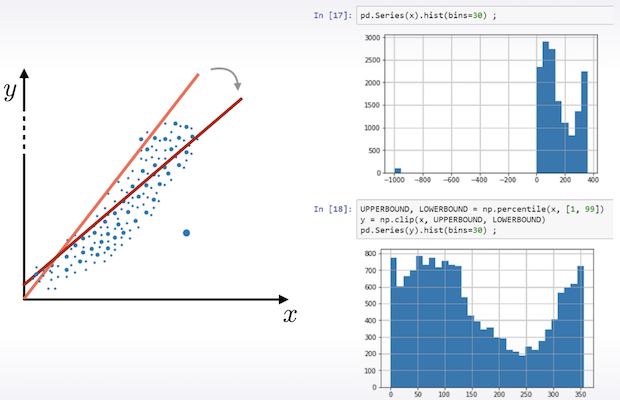
- Rank도 좋은 대안이 될 수 있다. 모든 값들의 간격을 동일하게 생성한다.
- Outlier가 있을때 MinMaxScaler를 적용하는 것보다는 훨씬 효과적이다.
- Linear models, KNN, Neural nets에서 전처리할 시간이 부족하다면 Rank가 효과적인 방안일 수도 있다.
- np.percentile 을 이용하여 1%, 99% 밖의 값을 제거하는 것이 효과적

03.Categorical and ordinal features
Categorical vs Ordinal
- Ordinal : Categorical + 순서에 따른 의미가 존재
- ex)
- Driver Licence Type : A > B > C > D
- 최종학력 : 유치원 < 초등학교 < 중학교 < 고등학교 < 학사 < 석사 < 박사
- ex)
Label Encoding
- 각 Category별로 code를 부여
- tree-model에서는 잘 동작하지만, non-tree-model에서는 혼란스러울 수 있음. 각 숫자크기별로 의미를 두어서 연산을 함
- Alphabetical (sorted)
- ex) [S,C,Q] -> [2, 1, 3]
- sklearn.preprocessing.LabelEncoder
- Order of appearance
- ex) [S,C,Q] -> [1, 2, 3]
- Pandas.factorize
- Ordinal 에서 의미상 순서대로 sorting된 경우에 사용하면 효과적이다.
- Alphabetical (sorted)
Frequency Encoding
- 각 Category별로 출현빈도(%)값을 부여
- ex) [S,C,Q] -> [0.5, 0.3, 0.2]
encoding = titanic.groupby(‘Embarked’).size() encoding = encoding/len(titanic) titanic[‘enc’] = titanic.Embarked.map(encoding)
- ex) [S,C,Q] -> [0.5, 0.3, 0.2]
from scipy.stats import rankdata- tree-model, linear-model 모두에게 효과적
- 하지만, 여러 feature들 간에 동일한 값을 가질수 있어서 그 중요도를 구분하기 힘들다.
One-hot Encoding
- linear-model에 효과적
- Category내 각각의 값들을 feature로 생성하여 해당하면 1, 아니면 0값으로 채움
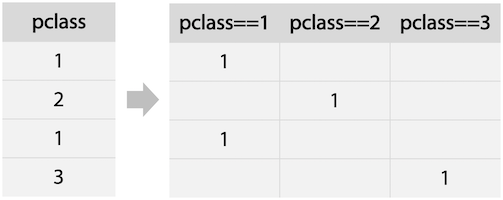
pandas.get_dummies, sklearn.preprocessing.OneHotEncoder
- 수백개의 binary feature가 생성될 수도 있음
- tree-model에서는 속도가 많이 느려져서 비효율적
- 2가지 이상의 feature를 mix하여 사용할 경우 효과적일 수 있음 : kNN, linear
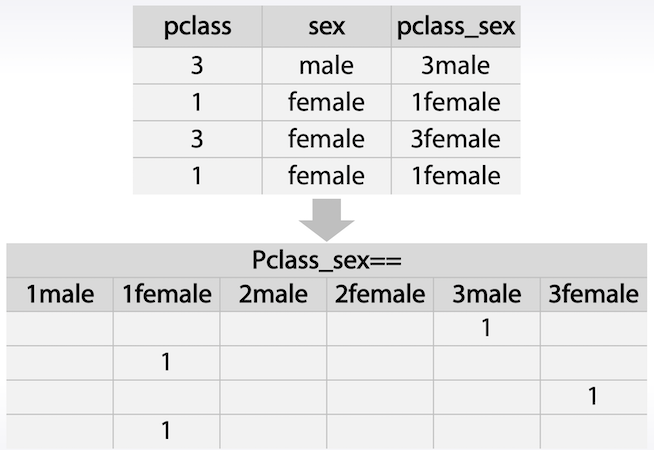
04.Datetime and Coordinates
Datetime feature
- Periodic
- year, month, day, hour, minute, second 별로 나누어서 반복성을 찾음
- season, week 등의 기준
- binary feature : workday/holiday, business time 등으로 나누는 방법도 있음
- 3일에 한번씩 같은 특정 패턴을 찾을때 유용하다.
- Time since
- 마지막 휴일 이후 얼마나 시간이 지났는지 / 캠페인이 끝날때까지 얼마나 남았는지 등을 고려
- Difference between dates
- 2개의 date feature 간의 차이 (diff)
- ex)
date_diff = last_call_date - last_purchase_date
- ex)
- 2개의 date feature 간의 차이 (diff)
Coordinate
- 중요 위치로부터의 거리
- 병원으로 부터의 거리, 가장 가까운 shop으로 부터의 거리
- 학습데이터 내에 그런 지점 정보가 없다면 추가로 생성하여 계산
- 지도를 분할하여 해당 지역내의 가장 비싼 지점으로부터의 거리
- 데이터를 클러스터링하여 그 중심으로 부터의 거리
- 주변 지역의 통계적 계산값
- Decision tree 기반의 모델의 경우 좌표값을 회전해서 사용하는게 더 효과적인 경우도 있음
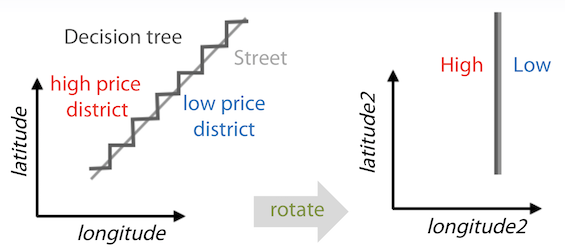
- 이 각도를 정확히 알기 힘들수도 있으니, 22.5 / 45 등 모든 각도로 회전한 것을 feature로 추가하는 방법도 있음
05.Missing values
- Missing value의 종류 : none, nan, 숫자가 아닌 값, 빈 문자값, -999 등…
- Missing value 그 자체로도 의미가 있을 수 있다. 왜 이 값은 비워져있을지를 먼저 고민해 보는 것도 필요하다.
Missing Value를 찾는 방법
- missingno 라이브러리 사용
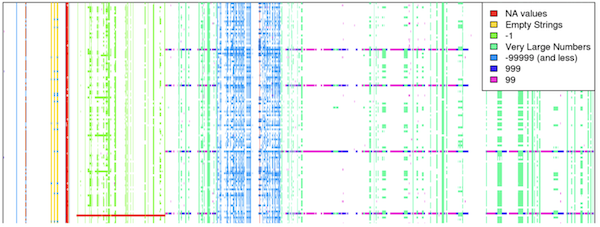
- http://www.xavierdupre.fr/app/jupytalk/helpsphinx/notebooks/im_missingno.html
import missingno
missingno.matrix(df)
missingno.heatmap(df)
missingno.dendrogram(df)
filtered_data = missingno.nullity_filter(df, filter='bottom', n=15, p=0.999)
missingno.matrix(filtered_data)
sorted_data = missingno.nullity_sort(df, sort='descending')
missingno.matrix(sorted_data.sample(250))
- Histogram 이용
- nan이라 표시되지 않는 missing value도 있는지 찾아봐야 한다.
- -1, 99 등의 숫자라고 해서 무조건 missing value가 아니라고 간주할 수는 없다.
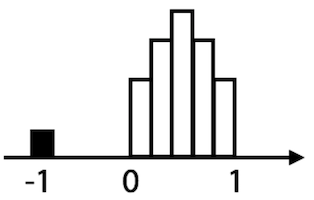
- 다른 모든 값들이 0 ~ 1 사이의 정규분포를 나타내는데 몇 개 안되는 숫자가 -1인 경우는 missing value라고 볼 수 있다.
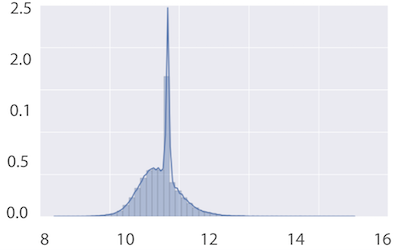
- x축의 평균을 벗어나는 값 ? 무슨 의미인지 잘…
- 터무니 없는 outlier 값
- ex) 기원전 또는 2025년에 작곡된 노래
Missing value 를 채우는 방법
- -999, -1 등 유요한 범위를 벗어나는 값
- Linear network에서 성능이 저하될 수 있음
- mean, median 등의 값
- Linear model과 Neural network에서 좋은 방법이 될 수 있다.
- 하지만 tree algorithm에서는 값이 누락된 객체를 선택하기에 어려울 수 있다.
- 이 경우에는 isnull feature를 추가하는 방법도 있다.
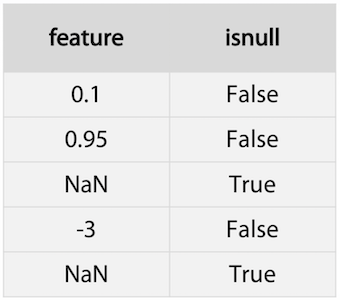
- 하지만 컬럼 수가 2배로 늘 수도 있다는 단점이 있다.
- 가능한 값으로 재구성
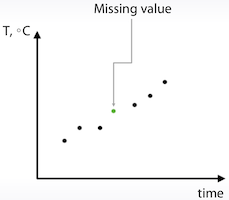
- 예를 들어 time-series 값일 경우 근사치로 값을 구할수 있음
- 하지만 대부분의 경우 각각의 row는 독립적이라 간주헤야하므로 이런 방법을 쓸 수 있는 경우는 거의 없다.
Missing value 채울 때 주의해야할 사항
- mean, median으로 채우면 안되는 경우
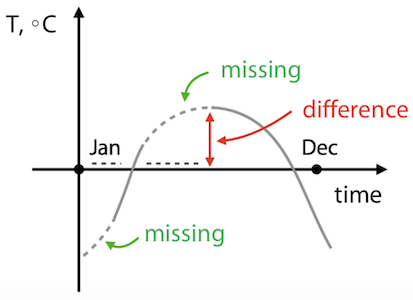
- daytime 과 온도값에 대해서 missing value가 위 그림과 같이 있는 경우, median으로 missing value를 채우면 실제 값과의 차이가 크게 날 수 있다.
- 이 케이스는 Interpolation(보간법)으로 채우는게 error를 줄일 수 있다는걸 알 수 있지만, 이렇게 판단할 시간이 충분하지 않을 경우에 missing value를 잘못된 방법으로 채웠다가는 왜 문제가 해결안되는지 찾기 힘들어 질 수도 있다.
- Feature generation을 하려는 경우
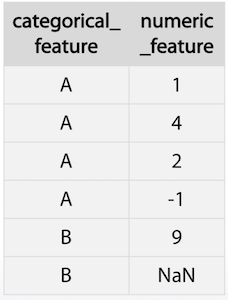
- category 별로 numeric의 평균값을 새로운 feature로 생성하려 할 경우, nan을 -999로 할경우 B 항목에 대해서는 값이 이상하게 된다. mean이나 median으로 채운다고 하더라도 비슷한 문제가 발생할 수 있다.
- 이 경우에는 새로운 feature를 먼저 생성한 후 missing value를 채워야 한다.
- Cetegorical feature 중 train에는 있지만 test에는 없는 경우
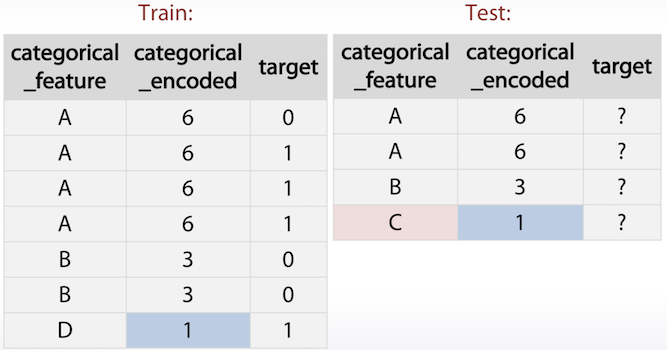
- 이 경우 predict시 random하게 처리할 확률이 높다.
- 해당 feature를 encoding 하여 비슷한 category로 묶는 것도 하나의 방법이 될 수 있다.
- 위 예제에서는 발생 빈도를 이용하여 encoded feature를 생성하였다.
- D와 C가 발생한 빈도가 비슷할 경우 발생 빈도가 target값에 의존성이 있다고 밝혀진 경우에는 C를 D로 간주할 수 있다.
Summary
- NaN값을 채우는 방법은 상황에 따라 다르다.
- 가장 대표적인 방법으로는 -999, mean, median으로 채우는 것이다.
- missing value가 이미 다른 값으로 대체되었을 수도 있다. 이 경우에는 histogram으로 조사가 가능하다.
- isnull 이라는 binary feature가 유용하다.
- feature 생성하기 전에 missing value를 채우는 것을 피하라.
- XGBoost는 NaN을 직접 처리 가능하며, 때로는 이것이 더 좋은 성능을 나타내기도 한다.
06.Feature extration from text and images
01.Bag of words
- Text 혹은 image 데이터만 있는 경우에는 neural network를 이용하면 되지만, 다른 데이터와 같이 있을 경우에는 이 것에서 feature를 만들어야 한다.
Text 데이터를 처리하는 방법은 크게 2가지가 있음
- Bag of words
- Embedding (like Word2Vec)
Bag of words
- 문장의 각 단어들이 몇 번 사용되었는지를 feature로 추출

- sklearn.feature_extraction.text.CountVectorizer
- 단순 출현 회수로만 가중치를 두어서 어느 것이 중요한 단어인지를 파악하기가 힘들 수도 있다.
- 불용어(관사, 전치사, 대명사 등 의미가 없는 단어)들이 많이 등장
- TFiDF
- Term Frequency : 문단 내에 자주 등장하는 단어에 높은 가중치를 둠
- inverse Document Frequency : 문서 내에 전체적으로 자주 등장하는 단어에는 가중치를 낮춤
sklearn.feature_extraction.text.TfidfVectorizer
- Term Frequency : 문단 내에 자주 등장하는 단어에 높은 가중치를 둠
- N-grams
- 단어들을 묶어서 feature로 생성
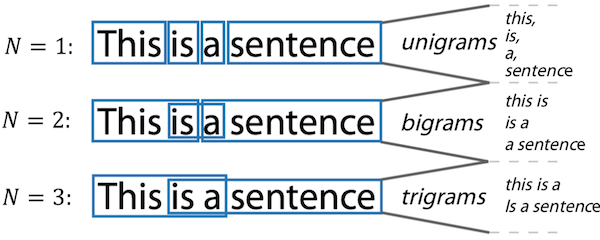
sklearn.feature_extraction.text.CountVectorizer:Ngram_range, analyzer
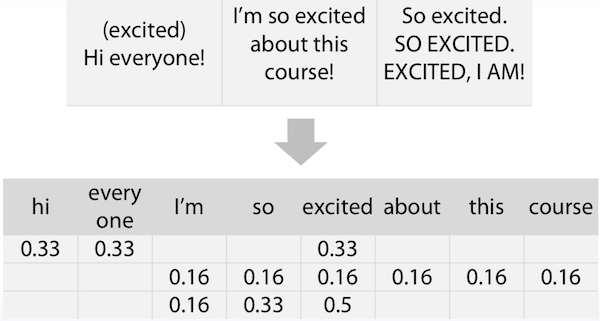
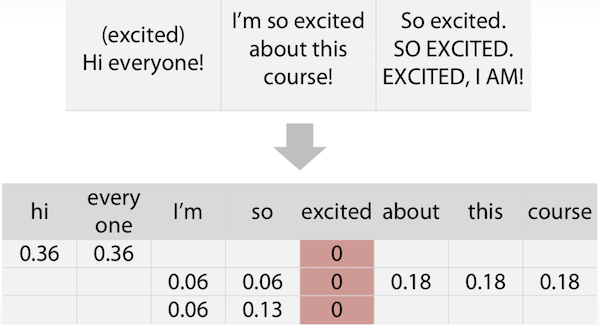
Text Preprocessing
- Lowercase
- 모든 단어를 소문자로 수정
- sklearn은 default로 lowercase로 수정하여 진행한다.
- Lemmatization ans Stemming
- 의미가 비슷한 다른 단어들을 같은 단어로 변환
- Stemming : 단어의 뒷부분을 없에버림
- Lemmatization : 단어의 의미를 분석하여 대표단어로 치환

- Stopwords (불용어)
- 모델에 아무런 영향을 끼치지 않는 의미가 없거나 너무나도 일반적인 단어들
- NLTK 등 자연어처리 라이브러리에 불용어가 잘 정의되어 있음
- sklearn.feature_extraction.text.CountVectorizer: max_df
- 불용어 리스트를 인자로 전달이 가능
Bag of Word의 Pipeline
- Preprocessing : lowercase, stemming, lemmatization, stopwords
- Bag of words (with N-grams)
- Postprocessing : TFiDF
02.Word2Vec & CNN
Word2Vec
- Bag of words 보다 간결하게 단어들을 vector화 시키는 방법
- Bag of words는 단어의 개수만큼 vector 차원을 사용해야 함
- 같은 context에서 사용되는 다른 단어들을 vector 공간에서 매우 가깝에 위치시키는 방법
- 이렇게 생성된 vector는 +, - 등의 기본 연산이 가능
- 종류
- 단어의 vector화 : Word2Vec, Glove, FastText
- 문장의 vector화 : Doc2Vec
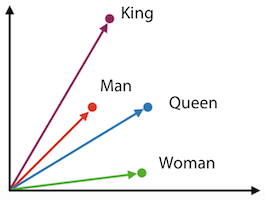
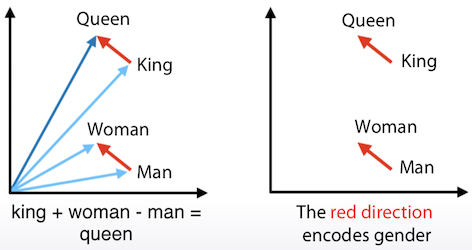
Bag of Words vs Word2Vec
Bag of Words Word2Vec
- vector의 크기가 큼 (단어 개수)
- vector의 값이 해석 가능
- 상대적으로는 작은 크기의 vector
- vector의 값은 유사한 관계라는 것을 의미
- 학습시간이 매우 오래 걸림
Convolutional neural networks
- 이미지를 처리하는데 이용
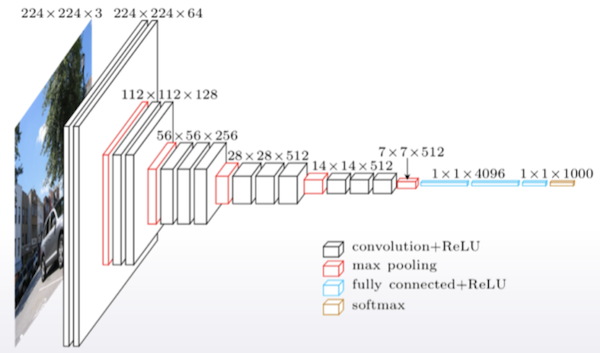
- 처음부터 모델을 학습시키는 것보다는 이미 잘 만들어진 모델을 가져와서 필요한 것들만 다시 훈련시키는게 더 효과적인 경우가 많다.
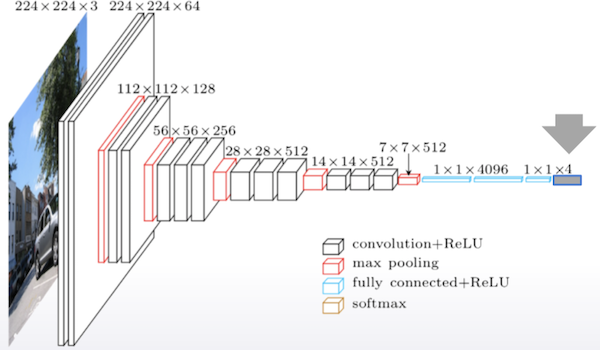
- Fine-tuning
- 다른 모델을 가져와서 우리의 목표에 맞게 수정
- 우리가 구해야할 결과가 4가지로 classification할 경우 위 model의 마지막 부분만 4개로 조정
- Argumentation
- 훈련 이미지가 많이 없을 경우 회전, 확대, 미러링 등을 이용하여 그 개수를 늘리는 것이 도움이 된다.
- 우리가 가진 지붕 데이터가 4개밖에 없을 경우 이 기법을 이용해서 더 늘리는 것이 가능하다.

이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
