Using AWS SageMaker to Tune Hyperparameter of XG-Boost
AWS SageMaker를 이용한 XG-Boost 하이퍼파라미터 최적화 방법 소개
1. Introduction to AWS SageMaker
AWS SageMaker는 머신러닝을 빠르게 구축, 학습 및 배포 할 수 있는 완전관리형 플랫폼이다. 이 서비스에 대한 자세한 설명은 AWS 공식 페이지 링크로 대신하겠다.
2. 하이퍼파라미터 튜닝에 SageMaker를 사용한 이유
Hyperparameter tuning은 굉장히 힘들고 오랜 시간이 걸리는 작업이다. Scikit-learn의 GridSearchCV를 사용해서도 할 수 있다. Scikit-learn과 SageMaker의 가장 큰 차이 점에 대해서 먼저 이야기해야 겠다.
Scikit-learn의 GridSearchCV는 우리가 입력한 Hyperparameter들에 대해서 모든 경우의 수를 다 테스트하여 그 중 가장 성능이 좋은 것을 결과로 준다. 해당 모델에서 지원하는 모든 Hyperparameter에 대해서 다 설정이 가능한 것이 가장 큰 장점이다. (SageMaker는 그렇지 아니하다.) 대신 Continuous Range 형식으로 값을 줄 수가 없다. 0.2 ~ 0.4 사이 값이라고 값을 줄 수가 없고, [0.2, 0.25, 0.3, 0.35, 0.4] 식으로 특정 값들을 줘야 한다. 그리고 우리가 준 Hyperparameter의 모든 경우에 대해서 다 학습을 한다. 만약 5개의 Hyperparameter에 대해서 5가지 값을 줬다면, pow(5, 5) = 3125번의 학습을 해야만 한다. 하지만, 어떠어떠한 값으로 테스트를 할지에 대해서 우리의 의도를 명확하게 설정할 수 있는건 큰 장점이다.
SageMaker를 이용할 경우에는 위에 설명한 것들과는 모두 다 반대되는 특징을 가진다. 모든 Hyperparameter에 대해서 설정이 가능하지 않다. SageMaker에서 지원해주는 Hyperparameter가 정해져 있다. 그래서 learning-rate에 대해서 값을 변경해보면서 하고 싶어도 그건 불가능하다. (이게 가장 큰 불만점이다.) 대신 Continuous Range로 값을 줄 수가 있다. 물론 SageMaker에서 이러이러한 값은 Continuous Range, 다른건 Integer Range, 다른건 Static한 값으로 고정, 이런 식으로 미리 정의가 되어 있다. 그래서 훨씬 편리하다. 이 경우 모든 경우의 수는 당연히 무한대이기 때문에 총 몇번의 학습을 해야 최적의 Model을 알 수 있는지에 대해서는 어느 누구도 장담을 못한다. 그래서 SageMaker는 당신이 입력한 경우에 대해서는 이게 최적이야. 라고는 답을 못준다. 대신 당신이 입력한 경우에 대해서 우리가 100번을 테스트 해본 결과 이게 최적이야. 라고 답변을 준다.
이게 좀 별로인것 같지만, 나에겐 생각보다 괜찮은 방법인것 같다. 왜냐면 최적의 Model을 알때까지 기다릴 필요가 없다. 일단 500번을 시도해서 나에게 그중 Best Model을 줘. 그럼 난 해당 Model로 일단 Learning 및 Predict를 진행을 하고, 이번에 나온 Best Model을 보고 Hyperparameter의 범위를 좀 더 좁힌 뒤 다시 500번의 테스트를 실행시킬 수 있다. 이런 식으로 지속적으로 Model의 개선이 가능하다. (우리는 지속적으로 비용을 지불해야 하고…) AWS는 진짜 천재인것 같다. 이런식으로 우리의 지갑을 털어가다니… (물론 내 지갑은 아니다. 회사일이니 회사 계정으로…)
3. Tutorial
SageMaker를 이용해서 Hyperparameter Tuning 하는 과정을 살펴보겠다. SageMaker에서는 일반적인 Training 및 학습시킨 Model을 배포하는 기능까지 제공하지만 그건 여기서 소개하지 않겠다. 왜냐면 난 그 기능을 사용하고 있지 않다. SageMaker에서 지원해주는 instance가 EC2에서 생성가능한 것들보다는 한단계 아래의 것들이다.
예제로 XG-Boost를 이용할건데, 다른 알고리즘에 대해서도 과정이 똑같을 것이라 판단된다.
AWS Console에서 선택을 해서 작업을 할 수도 있지만, 이번 예제에서는 그러지 않고 Jupyter Notebook 상에서 진행하겠다.
3.1 지원해주는 Algorithm 및 Hyperparameter 확인하기
SageMaker에서 우리가 무엇을 할 수 있는지 확인을 하기 위헤서 일단 AWS Console로 들어가 보겠다.
먼저 SageMaker의 Hyperparameter tuning job 탭으로 가서 우측 상단의 Create hyperparameter tuning job 을 눌러보자.
Job settings의 Hyperparameter tuning job name에는 아무 글자나 입력을 하고
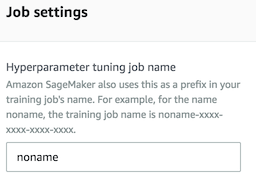
Training job configuration의 Algorithm을 눌러보면 지원되는 알고리즘의 목록이 나온다.
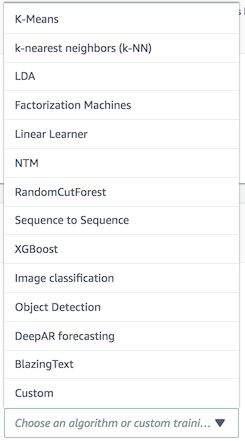
여기서는 XGBoost를 선택하면 아래에 CloudWatch 상에 생성된 Metric에 대해서 나오는데, 다음에 입력해야할 train, validation 방법에 대한 힌트를 얻을 수 있다.
Next를 누르면 다음 페이지에서 조정 가능한 Hyperparameter 들의 목록 및 어떤 값들을 넣을 수 있는지 확인이 가능하다.
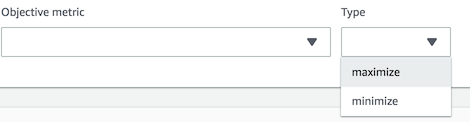
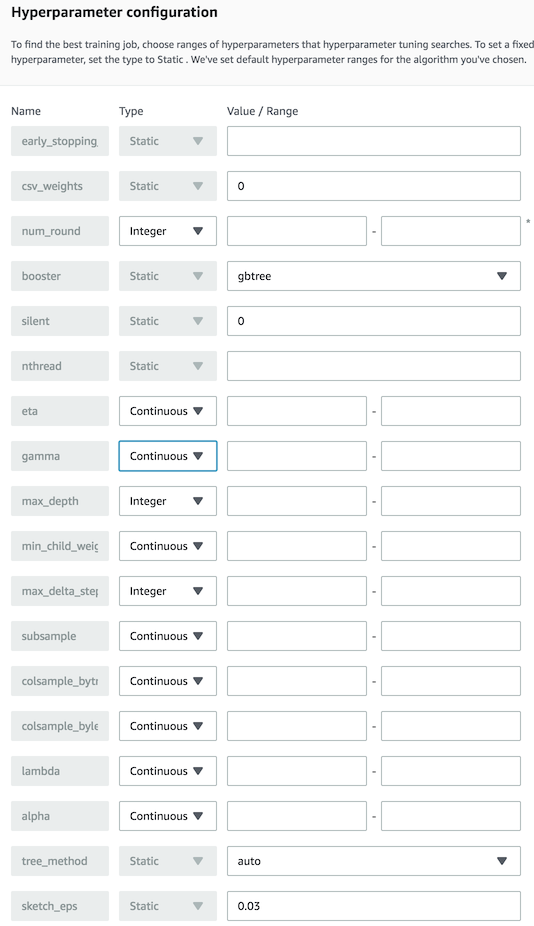
여기서 선택을 하고 Next로 가면서 계속해서 진행을 해도 가능하겠지만, 일단 여기까지만 확인하고 나가자.
3.2 예제 코드 확인하기
AWS에서 예제 코드들을 이미 제공을 해주고 있다.
위 Link에서 내용을 확인 할 수도 있고, SageMaker 상에서 Notebook Instance를 생성 한 뒤
그 곳에서 예제코드를 Notebook상에 만들어서 직접 실행 할 수도 있다.
하지만 한 번은 저 예제를 실행해야 한다. 그것도 SageMaker상의 Notebook Instance상에서. 왜냐면 RoleArn을 알아야 하기 때문이다. 그걸 알고 있다면 이 과정을 생략해도 된다.
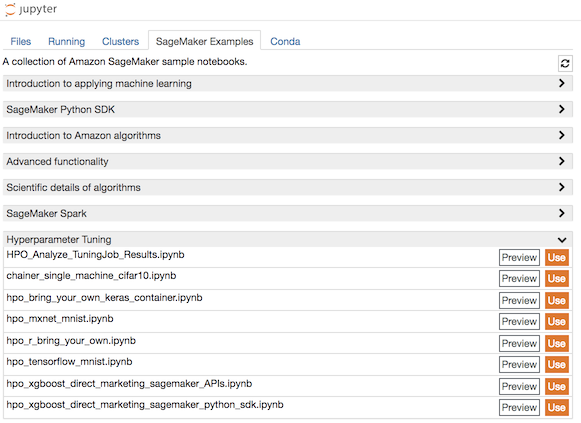
hpo_xgboost_direct_marketing_sagemaker_APIs.ipynb의 use를 누르면 해당 노트북이 Instance상에 복사된다.
노트북이 열리면 첫번째 cell을 실행 한 뒤 role 값에 대해서 확인을 한다.
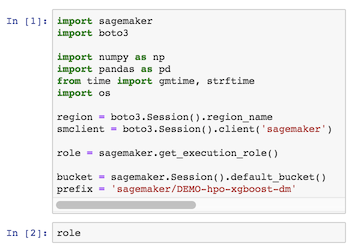
해당 문자열이 RoleArn이다. 이제 이것만 알면 SageMaker상의 Notebook Instance가 아닌 어느 PC에서도 작업이 가능해진다.
이 예제 파일에서 하는 일을 간단히 소개하자면 다음의 과정을 보여 준다.
Boto3,SageMaker패키지를 이용하여 접속- train, validation에 사용할 데이터 생성 : csv 형식
- 해당 파일 s3에 업로딩
- Hyperparameter Job 생성 및 실행
- 현재 실행상태 확인
앞으로 진행할 Tutorial도 해당 코드를 참고해서 작성한 것이다.
3.3 train, validation data를 S3에 업로딩
먼저 데이터를 S3에 업로딩해야한다. SageMaker를 사용하기 위해서 필수적으로 진행해야한다. 왜냐면 SageMaker는 S3에서 csv 파일로 읽어오는 방법만 현재 지원하기 때문이다.
해당 과정에 대해서는 따로 설명하지 않겠다. 기존 데이터를 이러한 형식으로 만드는 방법은 위에서 소개한 예제 코드에 자세히 나와있다. 꼭 그렇게 진행하지 않고 다른 방법으로 진행하여 S3에 직접 업로딩해도 된다. 단 아래의 규칙을 지켜야 한다.
- csv파일로 생성해야 한다.
- csv 파일의 경우 header가 없어야 하며, 첫번째 column값이
y(정답)이고 그 다음부터X(features)값들을 쭉 나열하면 된다. - train, validation 각각을 별도 폴더에 저장을 해야 한다.
SageMaker에서는 해당 폴더 내에 있는 csv 파일들을 읽어서 사용한다.
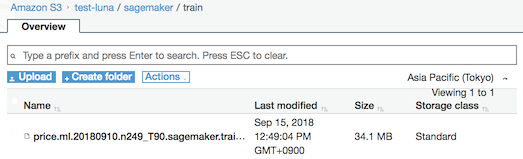
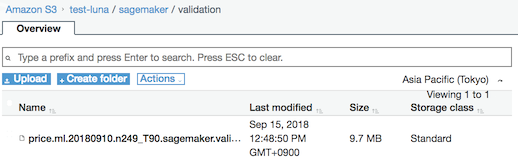
가능하면 같은 폴더 아래에 각각 train, validation이라는 이름의 폴더로 만들어 놓도록 하자. 왜냐면 그렇게 만들었다는 가정하에 아래 과정들을 진행할 것이기 때문이다.
3.4 Hyperparameter Tuning Job 생성
이제 Jupyter Notebook 으로 Hyperparameter Tuning Job을 생성해서 실행하는 코드를 소개하겠다.
먼저 boto3와 sagemaker가 설치되어 있어야 한다.
$ pip install boto3, sagemaker
이제 Jupyer Notebook에서 노트북 파일을 만든 뒤 아래 과정대로 cell에 입력하고 실행해보자.
import sagemaker
import boto3
session = boto3.Session(profile_name='my_profile') #~/.aws/profile에 정의해 놓은 AWS Profile Name
region = session.region_name
smclient = session.client('sagemaker')
boto3를 이용하여 SageMaker clinet를 생성한 것이다.
tuning_job_config = {
"ParameterRanges": {
"CategoricalParameterRanges": [],
"ContinuousParameterRanges": [
{
"MaxValue": "0.9999",
"MinValue": "0.0001",
"Name": "alpha",
},
{
"MaxValue": "0.9999",
"MinValue": "0.0001",
"Name": "eta",
},
{
"MaxValue": "20",
"MinValue": "1",
"Name": "min_child_weight",
},
{
"MaxValue": "0.9999",
"MinValue": "0.0001",
"Name": "colsample_bytree",
},
{
"MaxValue": "0.9999",
"MinValue": "0.0001",
"Name": "subsample",
}
],
"IntegerParameterRanges": [
{
"MaxValue": "30",
"MinValue": "5",
"Name": "max_depth",
},
{
"MaxValue": "2000",
"MinValue": "100",
"Name": "num_round",
}
]
},
"ResourceLimits": {
"MaxNumberOfTrainingJobs": 100,
"MaxParallelTrainingJobs": 10
},
"Strategy": "Bayesian",
"HyperParameterTuningJobObjective": {
"MetricName": "validation:mae",
"Type": "Minimize"
}
}
Tuning할 Hyperparameter에 대한 정의이다. 앞서 3.1에서 확인한 값들을 이용하여 정의하자.
from sagemaker.amazon.amazon_estimator import get_image_uri
training_image = get_image_uri(region, 'xgboost')
bucket = 'test-luna' #S3 Bucket Name.
prefix = 'sagemaker' # S3 Bucket에 test, validation 폴더가 생성된 상위 폴더까지의 path
s3_input_train = 's3://{}/{}/train/'.format(bucket, prefix)
s3_input_validation ='s3://{}/{}/validation/'.format(bucket, prefix)
s3_output = "s3://{}/{}/output".format(bucket,prefix)
role = 'arn:aws:iam::luna:role/service-role/AmazonSageMaker-ExecutionRole-20180915T103456' # 3.2에서 확인한 RoleArn
Hyperparameter Tuning Job에서 사용할 값들이다.
training_image: training에 사용할 알고리즘의 ECS 이미지 url이다. AWS에서 제공을 해준다. Custom Image를 이용해서도 가능하지만, 그럴 경우 AWS 공식문서를 확인해서 interface를 맞춰서 생성해야 한다.s3_input_train,s3_input_validation,s3_output:S3상에서의 train, validation 데이터가 저장된 경로, train 결과를 저장할 경로role:SageMaker를 실행할 권한이 있는 Role의 Arn
training_job_definition = {
"AlgorithmSpecification": {
"TrainingImage": training_image,
"TrainingInputMode": "File"
},
"InputDataConfig": [
{
"ChannelName": "train",
"CompressionType": "None",
"ContentType": "csv",
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "FullyReplicated",
"S3DataType": "S3Prefix",
"S3Uri": s3_input_train
}
}
},
{
"ChannelName": "validation",
"CompressionType": "None",
"ContentType": "csv",
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "FullyReplicated",
"S3DataType": "S3Prefix",
"S3Uri": s3_input_validation
}
}
}
],
"OutputDataConfig": {
"S3OutputPath": s3_output
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.c4.8xlarge",
"VolumeSizeInGB": 10
},
"RoleArn": role,
"StaticHyperParameters": {
"objective": 'reg:linear',
"learning_rate": '0.1'
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 43200
}
}
Hyperparameter Tuning Job에 대한 정의이다.
smclient.create_hyper_parameter_tuning_job(
HyperParameterTuningJobName = tuning_job_name,
HyperParameterTuningJobConfig = tuning_job_config,
TrainingJobDefinition = training_job_definition)
Hyperparameter Tuning Job을 생성하여 실행하는 코드다.
실행을 하면 AWS Console에서 실행 중인 것을 확인 가능하다.
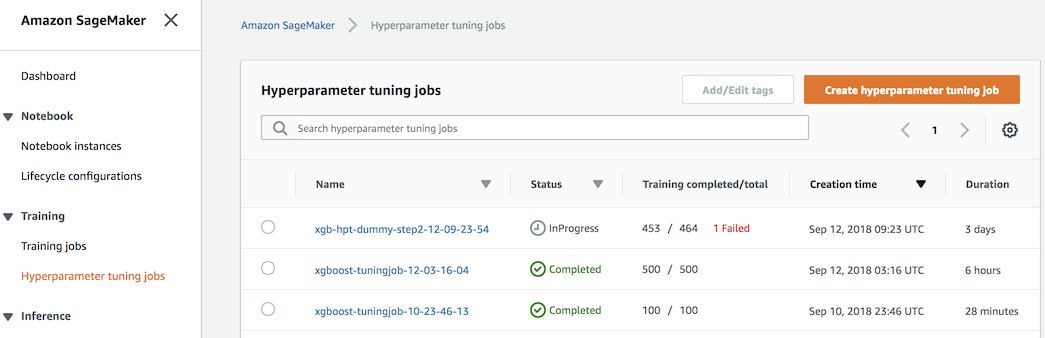
실행 상태를 코드로 확인하려면 아래와 같이 실행하면 된다.
smclient.describe_hyper_parameter_tuning_job(
HyperParameterTuningJobName=tuning_job_name)
그 중 중요한 것 몇가지만 소개하자면
HyperParameterTuningJobStatus: 현재 상태 InProgress, Completed, Failed, Stopped …BestTrainingJob: 현재까지 시도한 것중 가장Best Model의 정보, 수행시간,Hyperparameter정보 등등…
나머지 값들은 직접 확인하여도 어렵지 않게 이해가 가능하다.
Best Model의 정보는 작업 중 혹은 작업종료 후에 AWS Console에서도 확인이 가능하다.
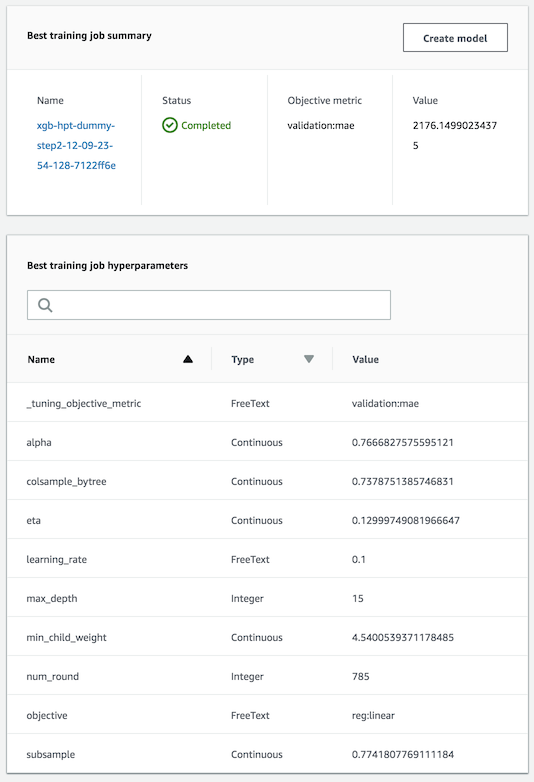
SageMaker에서 바로 Create model을 이용해서 작업이 가능하지만, 내 경우에는 작업은 따로 EC2를 생성하여 하였다. 그 이유는 아직 SageMaker에서 생성 가능한 instance의 성능이 EC2에서 생성가능한 것에 비해서 좋지 않아서 이다. 예를 들면 2018-09-15 현재 c시리즈 기준으로 EC2에서는 c5.18xlarge 까지 생성이 가능하지만, SageMaker에는 ml.c4.8xlarge가 가장 성능이 좋은 instance이다.
4. 맺음말
SageMaker를 사용해서 Hyperparameter Tuning을 하는 과정을 살펴보았다. 해당 작업을 업무에 실제로 사용해본 소감으로는 아주 편리했다. 하지만 Tuning 하고 싶은 값 중 아직 static으로만 입력이 가능한 것이 있어서 한편으로 아쉬움이 크다. 처음 사용할 경우 많은 부분들에 Limit가 걸려 있어서, support를 이용해서 늘려달라고 요청을 해야 한다. 그 과정이 대략 이틀 정도 걸렸다. 어느 정도 비용은 발생하지만 지속적으로 Model을 개선할 수 있는 것은 큰 장점이다.
혹시 질문사항이 있으면 언제든 댓글로 남겨주면 아는 한도 내에서는 답변을 드리겠다. 하지만 아직 SageMaker를 많은 부분에 사용하고 있지는 않아서 위 설명한 범위를 벗어나는 일반 Model의 학습 및 배포에 대해서는 현재로서는 SageMaker를 이용해서 할 계획이 없어서 답변이 가능할지에 대해서 현재로서는 미지수이다.
마치며…
잘못되었거나, 변경된 점, 기타 추가 사항에 대한 피드백은 언제나 환영합니다. - seokjoon.yun@gmail.com
이 글이 도움이 되셨다면 공감 및 광고 클릭을 부탁드립니다 :)
